University of Dayton, Department of Computer Science, CPS 491 - Capstone II, Spring 2021, Instructor: Dr. Phu Phung
Team members




Company Mentors
Novobi
Hung Nguyen hung.nguyen@novobi.com
8920 Business Park Dr #250, Austin, TX 78759
Project Overview
The overall goal of this project for Novobi is to:
- Upload an image of a document
- Parse the text from the image using an Optical Character Recognition engine
- Present the results to the user for verification
- Store in a database if correct.
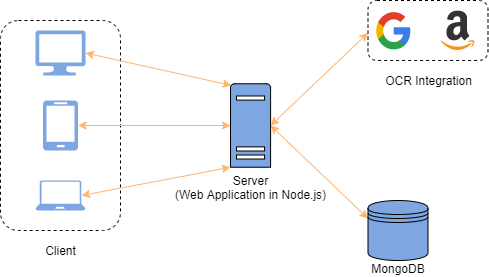
Project Architecture
Client/Server/Database architecture with OCR Integration
Technology
CSS3, HTML5, Node.js, MongoDB, Heroku, Javascript port of Tesseract Optical Character Recognition engine
Our Take On The Problem
We determined that one possible need for this type of application would be for a company that processes a large amount of invoice statements.
Someone in the accounting department needs to scan each paper invoice into the system to identify specific information in the document.
In order to do this we had to implement a solution for Zonal OCR, sometimes called Template OCR.
Zonal or Template OCR allows a user to define zones on a well-formatted document so that each time a document of that type is uploaded the same areas in the document are processed.
This allows only the relevant information to be pulled from the image.
The first step is to choose your template document and define where the relevant data is in the document.
The second step is to upload an image of a document that uses that same layout.
The final step is when you are presented with the results.
A user can choose to "accept" what was identified in the document and save it to the database.
A user can also reject the results. Perhaps the image resolution was too poor and the text that was identified was nonsense.
Lastly we also allow for specific zones to be modified by the uploading user (with the designated permission role) if perhaps something was not correctly identified in the image or certain information has changed.
It is up to the user that initially defines the zones on the template to determine which fields can and cannot be modified.
Project Outcome
Public Deployment On Heroku
Public Docker Image On Docker Hub
We were able to successfully implement a light-weight, dynamic Zonal OCR application. Our application can:
- Accept Template Document Images (not required to be an Invoice)
- Define Relevant Zones In The Template Document
- Parse and Display The Information For An Uploaded Document Using Previously Defined Zones
- Parse and Display The Information For An Uploaded Document In It's Entirety
- Display Previously Saved Document Parse Results